

Reframing ML problems | How does Netflix use ML to Improve Streaming Quality
Reframing ML problems | How does Netflix use ML to Improve Streaming Quality

Hi,
I hope you’re reading this email while keeping up in good health. This week I want you to ponder over how you frame your ML problems. I am going to introduce the reframing design pattern that breaks down the challenge of representing a problem.
Design patterns are a way of standardizing the experience and knowledge of experts to solve major challenges in any field. We have come too far in the field of AI and it’s high time we at least start discussing these design patterns.
Reframing
The Reframing design pattern solves the challenge of posing an intuitive machine learning problem with a changed contextual output. Here, we change the representation of the output of the problem. For example, an intuitive regression problem can be reframed into a classification problem and vice versa.
Let’s dive a little deeper to understand this.
Problem
Every machine learning project starts off by framing the problem. We try to answer questions like “Is this a supervised or unsupervised problem?”, “What features are we using?”, “If the problem is supervised, what is(are) the label?”, “What values of accuracy or error are acceptable?”. You try to answer these questions based on the data at hand and your business objective for building the model.
Take an example where we want to predict the amount of rainfall in a given location in a timeframe of 20 minutes. Now, this appears to be a straightforward time series forecasting problem and we’d be taking into account the historical climate and weather conditions to predict the amount of rainfall. Alternatively, this can also be defined as a regression problem as the label(amount of rainfall) is a real number(e.g. 0.5 cm).
After training your model a number of times, you realize that all your predicted rainfall amounts are off from the real values. The model says it’ll rain 0.2 cm but it actually rained 0.4 cm, surprisingly for the same set of features. The question arises how should we handle this uncertainty? How should we improve our predictions?
Solution
The key issue here is that amount of rainfall follows a probabilistic distribution. For the same weather conditions and features, it sometimes rains 0.2 cm, and other times it rains 0.4 cm. A regression model is limited to predict only a single number and the chances of getting it right are feeble.
Rather than trying to predict the amount of rainfall using a regression model, we can reframe our objective as a classification problem. This translation can be achieved using different ways. One way is to model the output as a multiclass classification using a discrete probability distribution. The model will return the probability of receiving rainfall in a certain range of amounts as shown below:
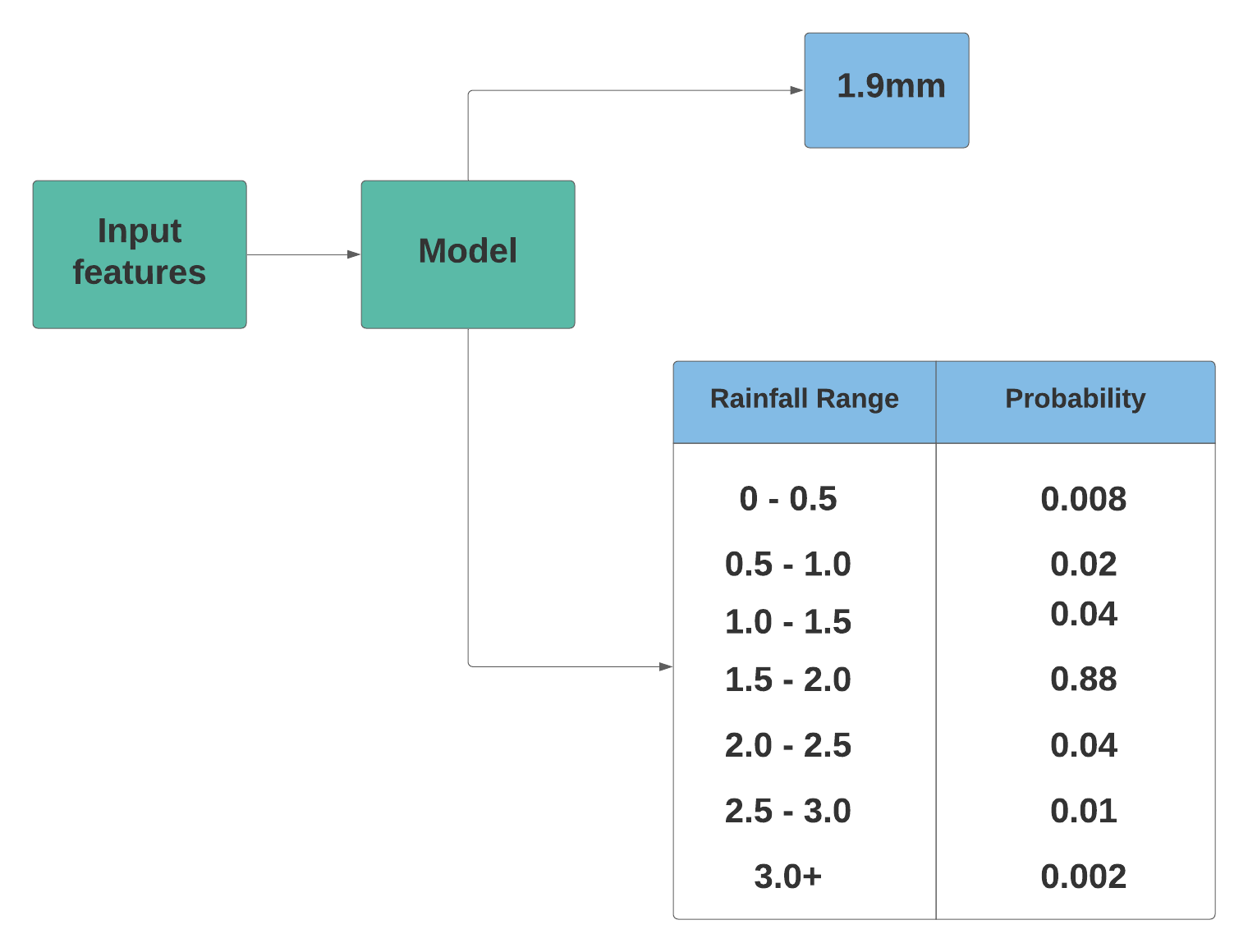
The classification model allows us to predict the probabilistic distribution of rainfall in different ranges rather than estimating the mean of the distribution. This method of modeling a distribution is advantageous since precipitation does not exhibit a normal distribution and instead follows a Tweedie distribution, which allows for a prevalence of points at zero.
The same approach was adopted in a Google research paper in which they documented a 512-way classification model to predict the precipitation rate in a given location.
Why It Works
Reframing a problem can help when building ml-powered applications. Instead of narrowing down our predictions to a single real number, we relax our prediction target to be a discrete probability distribution.
The trade-off comes in the form of lost precision due to bucketing but we gain the eloquence of a full probability density function (PDF). The rigid nature of regression models makes them less adept at learning as compared to such discretized predictions.
The other way round - when should we stick to regression?
There are cases when you’d want to reframe a problem into a regression task. One question that answers that question is how precise do we want our predictions to be?
The sharpness of the PDF(Probability Density Function) influences the precision of the regression model.

Sharper PDF points to a smaller standard deviation of the output distribution whereas a wider PDF indicates larger std. and hence more variance. It’s better to use a regression model in the case of very sharp density functions.
These reframing principles can be applied in a host of applications like building recommendation engines, customer segmentation, etc. Usually, we have multiple suitable approaches but what’s important is thinking holistically about the problem before you chart out the solution.
Interesting read of the week
This is a new section I’ve decided to add from this week onwards where I’ll share at least one interesting blog/article/chapter from a book that I read and enjoyed thoroughly.
This week’s interesting read was how Netflix is using ML to improve its streaming quality. The interesting part is how they framed this machine learning problem from the playback data that they are collecting while streaming to 117M viewers all around the world.
The blog explains the ideology of breaking down a complex problem of network quality and characterization and using statistical modeling to predict the throughput of a network in the next 15 minutes given the last 15 minutes of data. The sheer extent of the variables they take into consideration is mind-blowing. You’d enjoy reading this!
That’s it for this week, see you next Friday! Till then stay safe and wear a mask!